

AI is on the edge; or to be more precise, neural network acceleration is moving to the edge at a rapid pace. What used to require racks of cloud-based compute to run neural network inferencing can now be run on embedded devices such as cameras, smartphones and within vehicles.
With the evolution of dedicated hardware bringing greater compute power, networks are increasingly being optimized to run specifically at the edge. Markets such as smart camera surveillance, advanced driver-assistance systems (ADAS), autonomous vehicles, and mobile all have a need for data-driven decision making, based on input from real-time events. An autonomous vehicle has multiple cameras for computer vision, object recognition, lane warning, driver monitoring for fatigue as well as other sensors (e.g. thermal imaging, radar and LiDAR) for sensor fusion. By processing at the edge, this minimizes the bandwidth required to move data around the vehicle.
The advantage of dedicated IP for edge devices is in its compute density, exponentially more than other less specialized offerings. Neural networks have high bandwidth and computation requirements, but specialized design allows for optimal power, performance and area (PPA), maximizing inferences per second with minimal silicon area. This has the benefits of reduced latency and increased privacy (only sending relevant information through and not that of bystanders), with low power and bandwidth requirements thanks to the experience gained from the exacting PPA demands for the mobile space.
To deploy neural networks at the edge requires an understanding of the hardware on which they will run and the software frameworks that need to be extended, converted or designed for these edge-based deep learning accelerators. Converting to a fixed-point format offers a reduction in model sizes, compute and bandwidth. Tensorflow Lite is an example of this. Neural networks originally ran on CPU only. Some companies have used DSPs or FPGAs whilst others have focused on GPUs.
Pros and cons of deep learning inference-based computer vision processing
Although GPU acceleration can be 10 or more times faster than a CPU, the compute density offered by a dedicated accelerator in hardware can be exponentially faster than CPU and GPU.
Pros:
- Small but powerful, reaching the performance of cloud
- High performance per area and therefore lower silicon cost
- Low incremental cost for density making it ubiquitous for IoT devices
- Does not necessarily require connectivity, making it ideal for standalone devices, or low power, low bandwidth
Cons:
- Can execute tasks but models must be compiled for target hardware
- Not suitable for training
- May still require significant power depending on configuration
- Flexibility of task-specific solutions
What processing role does 'the cloud' play in such a scheme?
The cloud plays a complementary role to embedded edge processing - indeed they are symbiotic. Training, validation and retraining are often best run in the cloud as these are "big tin" tasks, requiring thousands of processing units. Meanwhile, the edge can run a network that is task-specific, or multiple devices can run a series of neural networks - for sensor fusion for example. So, it's not "either or"; it's "both and."
Whenever there are challenges to be overcome about latency, transmission, security or cost, edge devices can help. By running inferencing on a device with a neural network accelerator smaller than a pinhead, these tiny devices have big applications across the entire world of markets - including, but not limited to, security, retail, connected homes, education, agriculture and health.
Looking to the future
Looking ahead, requirements for edge device capability are likely to increase. This will be complemented by the 5G rollout, enabling devices to "phone home" to update their neural network models and of course, to transfer important findings to the central computer - vital for effective ambient/pervasive computing.
Performance, power consumption and memory implications are all the focus of ongoing work, with companies vying to produce the optimal device at the lowest possible area cost. We are on the edge of a future in which devices "see" and importantly "recognize" - as a step forward towards a data-driven future. So, the fourth industrial revolution won't be in the datacenters; it'll be in the streets, the fields, the shopping malls and the factories, in devices, robots and vehicles. It will be all pervasive and all but invisible - but it will be ubiquitous.
(Andrew Grant is senior director, PowerVR AI, Imagination Technologies)
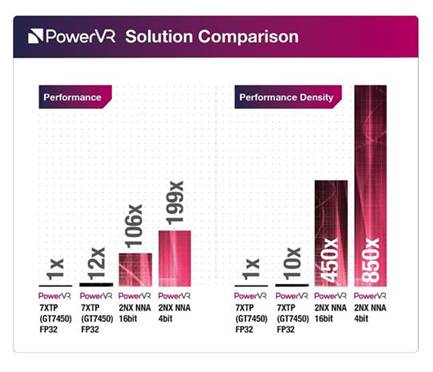
Compute density
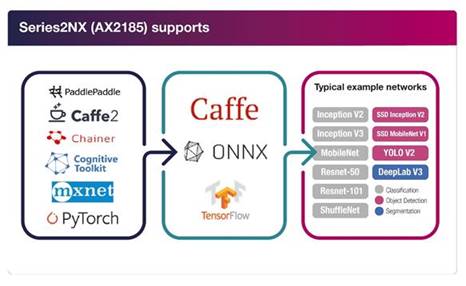
Example neural networks
DIGITIMES' editorial team was not involved in the creation or production of this content. Companies looking to contribute commercial news or press releases are welcome to contact us.

